Política de Ação em Incidentes de Indisponibilidade :: NovoAvanço
Objetivo
Estabelecer um processo padronizado de resposta a incidentes de indisponibilidade total ou parcial do NovoAvanço, abrangendo os ambientes infovarejo, avancoinfo e piracuera, com foco em:
-
Cauterização imediata do impacto
-
Registro técnico no Datadog
-
Acionamento da Squad de Produto para análise da causa raiz
Quando esta política deve ser acionada?
Sempre que for constatada queda, lentidão severa, falha de acesso ou interrupção total/parcial do sistema NovoAvanço em qualquer ambiente.
Etapas do Processo
1. Disparo do Plano de Contingência
Assim que a indisponibilidade for detectada (por cliente, equipe interna ou monitoramento automático), deve-se:
-
Iniciar imediatamente a investigação técnica da origem do problema
-
Aplicar ações de contenção/cauterização, mesmo que envolvam medidas agressivas, como:
-
Execução de queries emergenciais
-
Escalonamento de recursos computacionais (ECS, RDS, etc.)
-
Rollback de versão
-
Retry forçado em pipelines
-
🔁 O objetivo nesta fase é restabelecer a disponibilidade do sistema o mais rápido possível, mesmo que de forma temporária.
2. Investigação Técnica pela Squad 2.E
A Squad 2.E será a responsável por:
-
Identificar a origem técnica do incidente:
-
Query ofensiva
-
Rota/API defeituosa
-
Processo interno sobrecarregando o sistema
-
Erro em deploy ou pipeline
-
-
Formalizar a descoberta no Datadog Incident Page:
-
Criar o incidente com as informações descritas no modelo abaixo
3. Modelo de Preenchimento do Incidente (Datadog)
Título (Title)
PRODUTO - E O QUE ACONTECEU
Exemplo:
NOVO.INFOVAREJO – LENTIDÃO SEVERA
Severidade (Severity)
Crítica (padrão para qualquer indisponibilidade que impacta o cliente final)
Origem da Detecção (Detection Method)
-
Customer→ relato de cliente -
Employee→ relato de colaborador Avanço -
Monitor→ alerta automático Datadog ou AWS
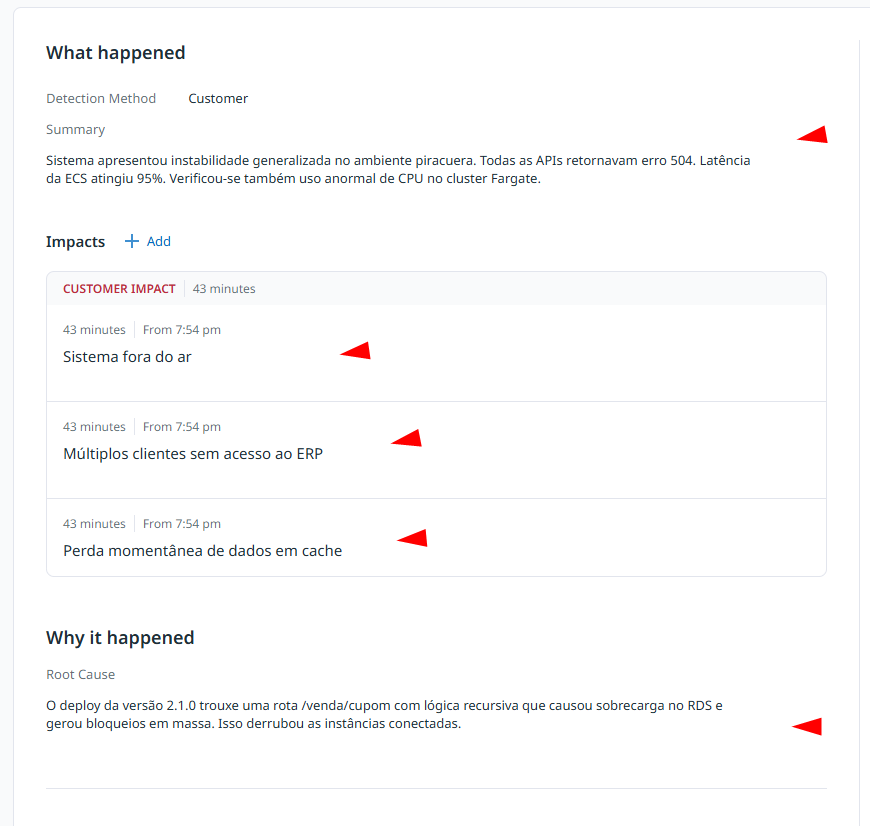
Summary
Descrição objetiva do ocorrido.
Exemplo:
"Sistema apresentou instabilidade generalizada no ambiente piracuera. Todas as APIs retornavam erro 504. Latência da ECS atingiu 95%. Verificou-se também uso anormal de CPU no cluster Fargate."
Impacts
Relatar impactos reais e diretos do problema.
Exemplo:
Sistema fora do ar
Múltiplos clientes sem acesso ao ERP
Perda momentânea de dados em cache
Why it happened
Apontamento técnico da causa raiz.
Exemplo:
“O deploy da versão 2.1.0 trouxe uma rota/venda/cupomcom lógica recursiva que causou sobrecarga no RDS e gerou bloqueios em massa. Isso derrubou as instâncias conectadas.”
Remediation
Dividir entre:
-
Ação emergencial aplicada (para restabelecer)
Exemplo: “Rota desativada via hotfix + scale out no serviço ECS”
-
Ação de resolução definitiva (para squad responsável)
Exemplo: “Card criado para reescrita da rotina recursiva e aplicação de limite de chamadas na API”
Exemplo de Preenchimento:
4. Encerramento da Fase de Cauterização
Assim que o sistema for restabelecido, deve-se:
-
Atualizar o status do incidente no Datadog para
stable -
Garantir que todos os campos foram preenchidos
-
Enviar o link do incidente ao Squad Leader do produto afetado
5. Criação de Card para Resolução Definitiva
O QA ou líder da Squad responsável pelo produto afetado deverá:
-
Criar um card com prioridade urgente no board do time
-
Associar o link do incidente Datadog
-
Detalhar os pontos levantados no campo Remediation
- Ao concluir o card, o QA deve alterar o status do incidente no Datadog para
Resolved - Incluir um Follow-up do incidente no datadog com o link do card
Responsabilidades
| Etapa | Responsável |
|---|---|
| Identificação e cauterização | Squad 2.E |
| Criação e preenchimento do incidente no Datadog | Dev de plantão ou tech da Squad 2.E |
| Comunicação ao Squad responsável | Tech da 2.E ou Tribe Leader |
| Criação de card de resolução definitiva | QA ou líder da Squad do produto afetado |
Reflexão: Por que isso é importante?
A aplicação rigorosa deste processo não é apenas uma questão operacional, ela é estratégica.
Qualquer avanço no produto, seja em usabilidade, vendas, novos recursos, melhorias no onboarding, amadurecimento do time de serviços e implantação, perde valor se a sustentação básica do sistema não estiver garantida.
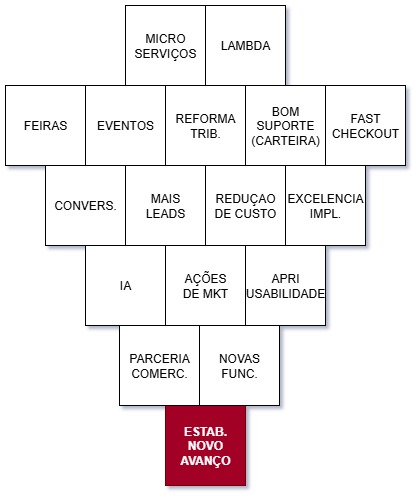
A indisponibilidade recorrente gera:
-
Desconfiança do cliente sobre o produto
-
Sensação de insegurança com os dados
-
Medo de operar no sistema em horários críticos
-
Comprometimento da credibilidade da Avanço como fornecedora de tecnologia
Em outras palavras, sem confiança na estabilidade da plataforma, não há margem para crescimento sustentável. É impossível consolidar a jornada de evolução tecnológica de nossos clientes se o básico , disponibilidade e continuidade do serviço, não for garantido com excelência.
Essa política de contingência é, portanto, uma camada de proteção estratégica para a reputação da empresa, para a tranquilidade do cliente, para o estabelecimento da melhoria contínua e para o próprio futuro do produto.